- The AI Report
- Posts
- 🧠 vs 🤖
🧠 vs 🤖
Even the Smartest AI Fails This New Test
The AI Report
April 01, 2025
In partnership with
AI evolution hit warp speed this week. While Google's Gemini thinks before it speaks and Chinese models run on MacBooks, a humbling new benchmark shows most AI models scoring like toddlers on an adult exam – humans still lead 60% to 1% on the toughest tests of general intelligence.
The Latest in AI:
🚀 Gemini 2.5 Rewrites AI Rules
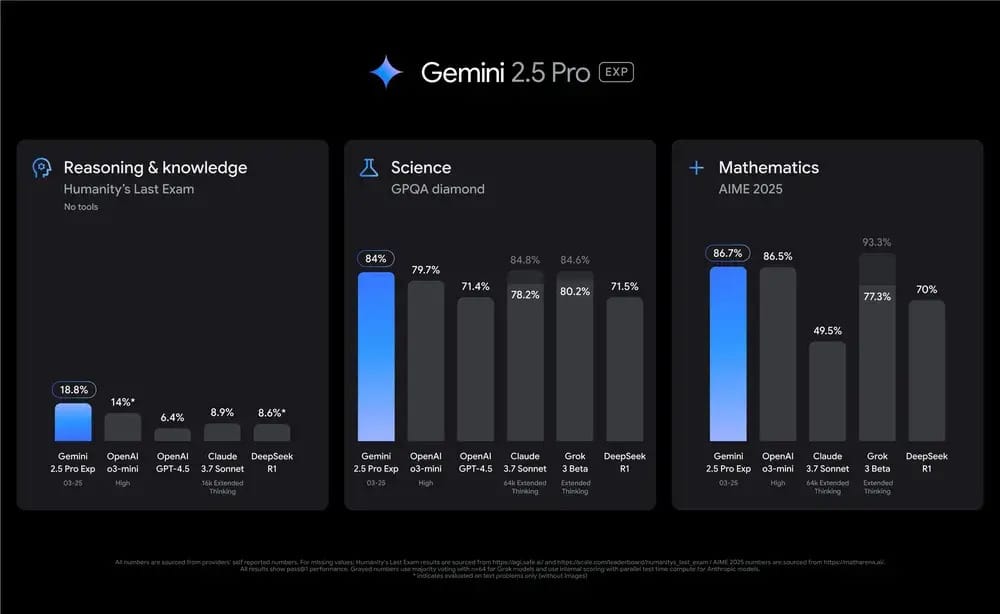
Google just raised the bar for AI assistants with a model that thinks before it speaks. The latest Gemini release represents a significant leap in reasoning capabilities and context handling.
Google has unveiled Gemini 2.5 Pro, described as its "most intelligent AI model" to date, featuring built-in "chain-of-thought reasoning" that allows it to think through problems internally before responding.
The model debuts at #1 on the LMArena leaderboard by a significant margin and leads in coding, math, and science benchmarks, scoring 18.8% on Humanity's Last Exam compared to OpenAI's 14% and Anthropic's 8.9%.
Gemini 2.5 Pro boasts a massive 1 million token context window (with 2 million coming soon), enabling it to process hundreds of pages or entire code repositories at once.
It achieves a 63.8% success rate on the SWE-Bench coding benchmark, showing substantial improvements over previous models but still trailing Anthropic's Claude 3.7 "Sonnet" (70.3%).
Google is retiring the separate "Flash Thinking" branding, as reasoning capabilities are now built into all future models by default.
🤔 Why It Matters:
This release marks Google's resurgence as a frontrunner in the AI race, challenging the narrative that they've been lagging behind OpenAI and Microsoft. The integration of reasoning as a default feature, rather than a special mode, signals a fundamental shift in how AI assistants will function moving forward. For developers and businesses, Gemini 2.5 Pro's combination of coding prowess and massive context window could dramatically accelerate software development cycles while enabling new forms of automation for knowledge work across industries.
The first search engine for leads
Leadsforge is the very first search engine for leads. With a chat-like, easy interface, getting new leads is as easy as texting a friend! Just describe your ideal customer in the chat - industry, role, location, or other specific criteria - and our AI-powered search engine will instantly find and verify the best leads for you. No more guesswork, just results. Your lead lists will be ready in minutes!
💣️ DeepSeek Unleashes Local AI Power
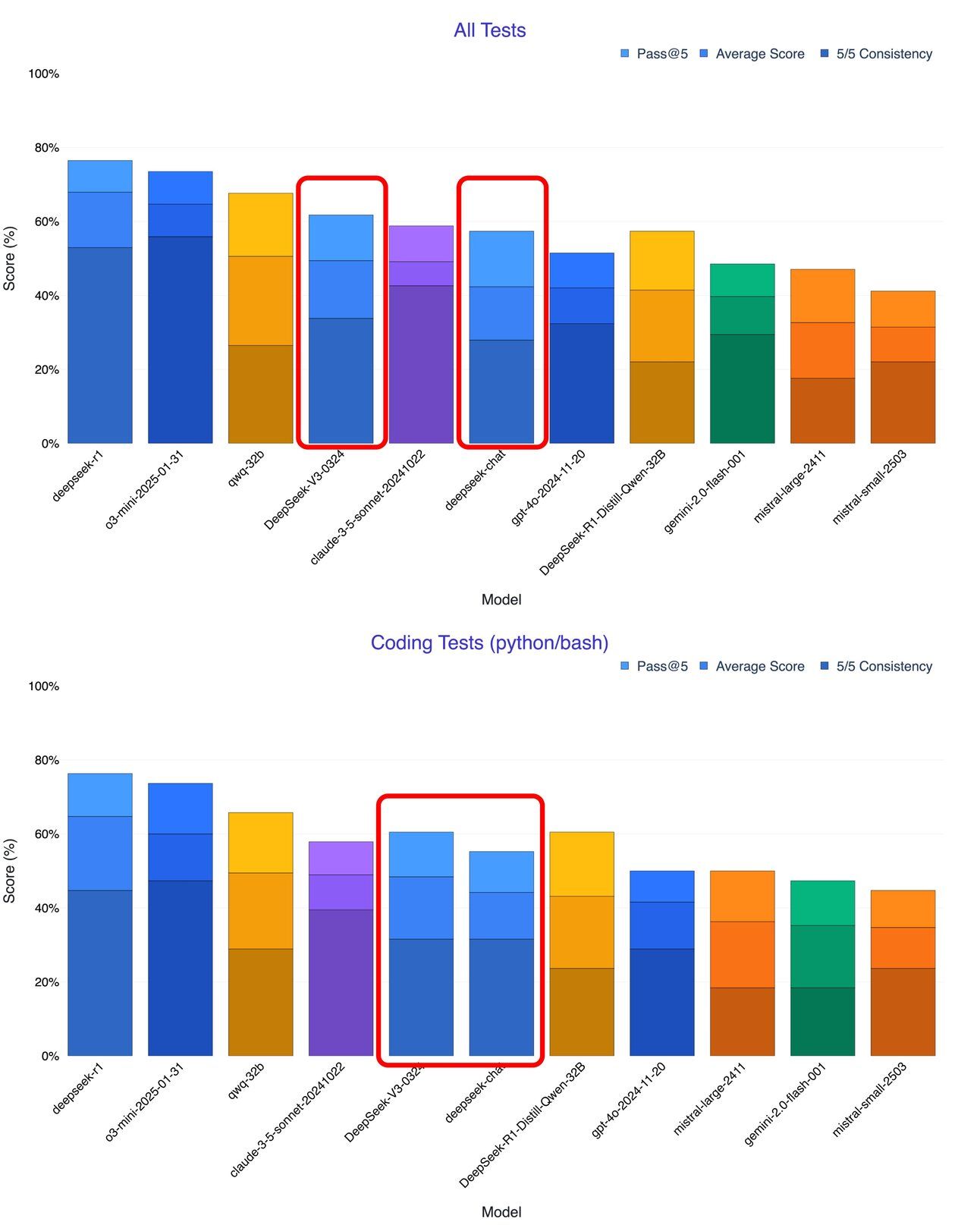
The AI industry's assumption that cutting-edge models require massive data centers is being challenged. DeepSeek's latest release brings powerful AI to consumer hardware with an open-source approach that could disrupt established players.
Chinese AI startup DeepSeek has quietly released DeepSeek-V3-0324, a 685-billion-parameter model available under an MIT license for free commercial use.
The model runs at over 20 tokens per second on consumer hardware like Apple's Mac Studio with M3 Ultra chip, challenging the assumption that state-of-the-art AI requires data centers.
DeepSeek-V3 uses a mixture-of-experts (MoE) architecture that activates only 37 billion of its 685 billion parameters for specific tasks, dramatically improving efficiency.
Early testers report it outperforms Anthropic's Claude Sonnet 3.5, making it "the best non-reasoning model" available, despite being freely accessible while Sonnet requires a subscription.
The model represents a strategic shift from Western AI companies' closed API approach to China's open-source AI revolution, potentially democratizing access to cutting-edge AI technology.
🤔 Why It Matters:
DeepSeek's release fundamentally challenges the Western business model of keeping AI models behind paywalls and API services. By enabling local deployment on consumer hardware, it removes both cost barriers and privacy concerns associated with cloud-based AI services. This could accelerate AI adoption across industries and geographies currently underserved by subscription models, while forcing companies like OpenAI and Anthropic to reconsider their closed ecosystem strategies.
🧩 New AGI Benchmark Challenges AI Models

Even the most advanced AI systems are failing at what humans find intuitive. A new test from the Arc Prize Foundation reveals the persistent gap between artificial and human intelligence in adaptive reasoning.
The Arc Prize Foundation has released ARC-AGI-2, a new benchmark designed to measure general intelligence in AI models by testing pattern recognition in grid-based puzzles.
Even the most advanced AI models struggle with the test - "reasoning" models like OpenAI's o1-pro and DeepSeek's R1 score only 1-1.3%, while GPT-4.5, Claude 3.7 Sonnet, and Gemini 2.0 Flash achieve around 1%.
Human participants significantly outperform AI, with panels of people solving 60% of the test questions correctly.
The new benchmark focuses on efficiency as a key metric, evaluating not just whether an AI can solve problems but how efficiently it acquires and applies new skills.
OpenAI's o3 model, which previously dominated the original ARC-AGI-1 test with human-level performance, achieves only 4% on ARC-AGI-2 despite using $200 worth of computing power per task.
🤔 Why It Matters:
ARC-AGI-2 reveals a persistent gap between human and machine intelligence when it comes to efficient adaptation to novel problems. This benchmark provides a much-needed reality check on AI progress claims, demonstrating that even the most advanced models struggle with the kind of flexible reasoning that humans find intuitive. For AI developers, this creates a clear north star for improvement while giving businesses a more realistic understanding of current AI limitations in tasks requiring true adaptive intelligence.
Start learning AI in 2025

Keeping up with AI is hard – we get it!
That’s why over 1M professionals read Superhuman AI to stay ahead.
Get daily AI news, tools, and tutorials
Learn new AI skills you can use at work in 3 mins a day
Become 10X more productive
🗞️ AI Bytes
📰 Ideogram 3.0 Transforms Design Landscape
Using this new tool is like having a professional design team in your pocket. Businesses are churning out slick marketing materials in seconds that would have taken days and thousands of dollars before.
📰 Peek Inside Claude's Brain Reveals Surprising Secrets
Anthropic's researchers caught Claude "planning" poetry rhymes several words ahead—unlike humans who typically improvise. When given incorrect hints, the AI sometimes fabricates convincing but fake reasoning chains to please users.
📰 AI Coding Tools: The Gold Rush Nobody Expected
The digital equivalent of the 1849 Gold Rush is happening—but it's the code miners, not the prospectors, being replaced. Tools like Cursor hit $100M revenue in under a year while engineers switch platforms monthly in search of the perfect assistant.
📰 GPT-4o Turns Words Into Pixel-Perfect Reality
OpenAI's latest image generator doesn't just create pretty pictures—it thinks about them first. The model's deep knowledge lets it produce graphics that actually make sense, right down to accurately rendered text that's stumped other AI tools for years.
🛠️ Top AI Tools This Week
🤖 SimplA
This versatile platform enables developers to build, deploy, and manage AI agents across on-premises, cloud, or hybrid environments without infrastructure headaches. SimplA streamlines the complex process of implementing agentic AI into existing workflows with a unified interface.
📊 CRO Benchmark
This conversion rate optimization tool analyzes your landing pages against more than 100 data points to identify user friction points and improve conversion. The platform automatically compares your site against competitors and provides customized suggestions based on your specific traffic patterns.
On a scale of 1 to AI-takeover, how did we do today? |